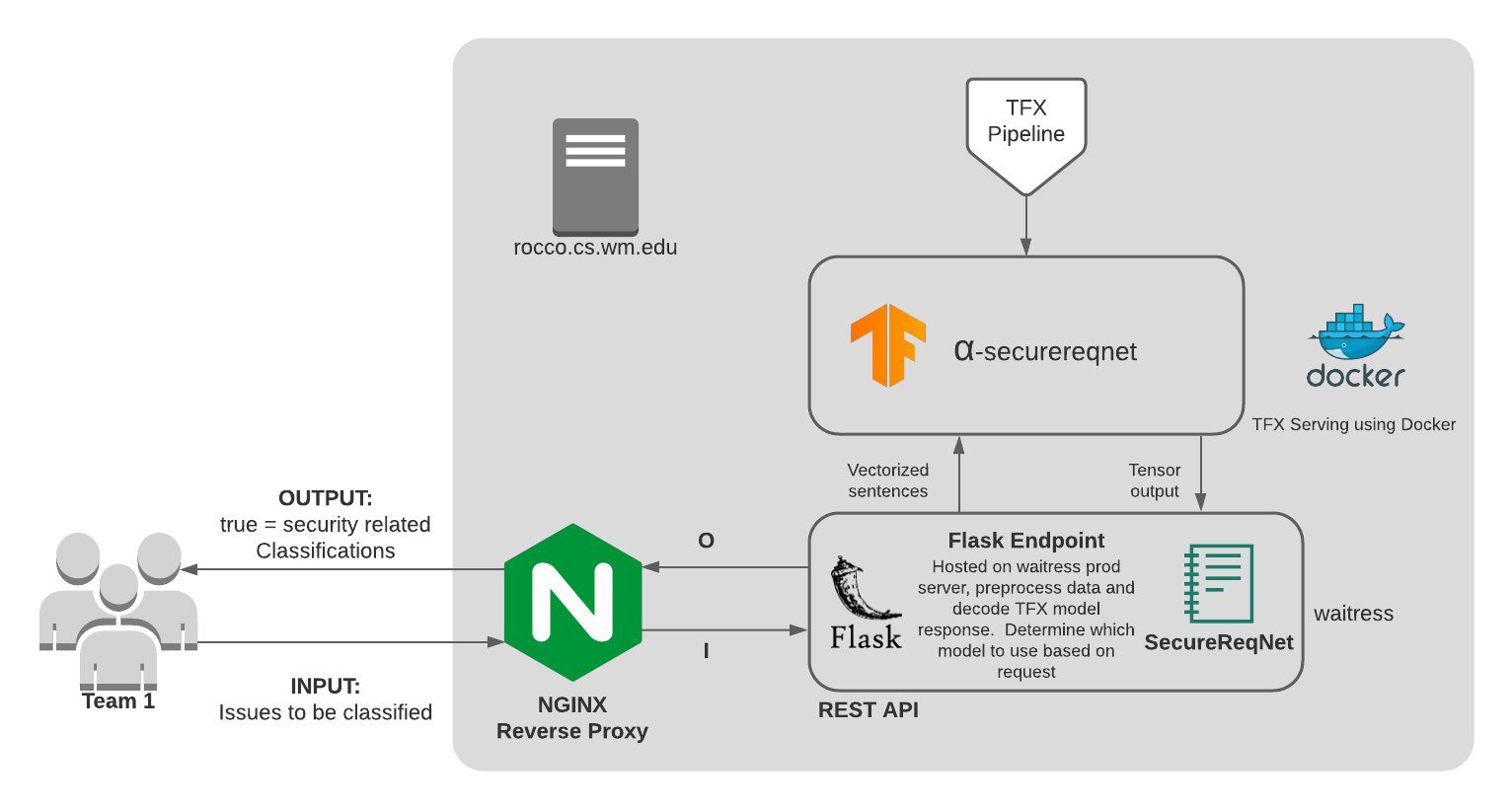
We present a machine learning approach, named SecureReqNet, to automatically identify whether issues describe security related content. SecureReqNet hinges on the idea of predicting severity on software using vulnerability desciptions (Han, et al., 2017) by incorporating desing principles from AlexNet (Krizhevsky, et al., 2013).
Want to try out SecureReqNet? Checkout these examples in google colab:
α-SecureReqNet:
https://colab.research.google.com/drive/1mOXvgvkqCEgrAahyUH9Bw0ZO_nLglNFq
Γ-SecureReqNet:
https://colab.research.google.com/github/wm-semeru/SecureReqNet/blob/master/Gamma_SecureReqNet.ipynb
Or serve your own version:
https://colab.research.google.com/drive/1pb_QQOm0jA0SwejgqxBXKBhkuM42al4k
For model interpretability:
https://colab.research.google.com/drive/1C4D4Wvv0xW8UfoFNLM-7Bc2NxP0AISvB
Research and Components Roadmap
- [x] Using Shallow Neural Network to predict security relatedness on issues (or requirements)
- [x] Using Deep Neural Network to predict security relatedness on issues (or requirements)
- [ ] Using a Neural Network to predict quantitatively (regression) how critical is an issue (or requirement)
- [ ] Implementing a Transformer Architecture to predict security criticality on issues (or requirements)
- [ ] Recovering security related relationships among software artifacts by employing traceability theory
SecureReqNet consists of a two-phase deep learning architecture that operates (for now) purely on the natural language descriptions of issues. The first phase of our approach learns high dimensional sentence embeddings from hundreds of thousands of descriptions extracted from software vulnerabilities listed in the CVE database and issue descriptions extracted from open source projects using an unsupervised learning process. The second phase then utilizes this semantic ontology of embeddings to train a deep convolutional neural network capable of predicting whether a given issue contains security-related information.

SecureReqNet has four versions that vary in terms of the size of the tensors and the parameters of the convolutional layers.
- SecureReqNet (shallow) was based on the best architecture achived by Han, et al. Such architecture implemented one convolution layer with 3 kernes of different sizes. The authors set up the size of each kernel as 1-gram, 3-gram, and 5-gram to reduce an input matrix. This matrix was built by means of an unsupervised word2vec where the rows represents the words in a given document (or issue) and the columns the size of the embedding. Details of how we trained our word2vec can be found in the notebook 03_Clustering. SecureReqNet (shallow) has a max pooling layer followed by a flatten function. The final tensor is a merged vector from the 3 initial kernels. Unlike Han, et al.' SVM multi-class output layer, we utilized a binary classification throughout a softmax layer.
# 1st Convolutional Layer (1-gram)
conv_filter_1_gram = Conv2D(filters= N_filters, input_shape=input_sh, activation='relu',
kernel_size=(1,embeddigs_cols), padding='valid',data_format="channels_last")(gram_input)
# 2sd Convolutional Layer (3-gram)
conv_filter_3_gram = Conv2D(filters= N_filters, input_shape=input_sh, activation='relu',
kernel_size=(3,embeddigs_cols), padding='valid')(gram_input)
# 3rd Convolutional Layer (5-gram)
conv_filter_5_gram = Conv2D(filters= N_filters, input_shape=input_sh, activation='relu',
kernel_size=(5,embeddigs_cols), padding='valid')(gram_input)
# Max Pooling Layer
max_pool_1_gram = MaxPooling2D(pool_size=((max_len_sentences-1+1), 1), strides=None, padding='valid')(conv_filter_1_gram)
max_pool_3_gram = MaxPooling2D(pool_size=((max_len_sentences-3+1), 1), strides=None, padding='valid')(conv_filter_3_gram)
max_pool_5_gram = MaxPooling2D(pool_size=((max_len_sentences-5+1), 1), strides=None, padding='valid')(conv_filter_5_gram)
# Fully Connected layer
fully_connected_1_gram = Flatten()(max_pool_1_gram)
fully_connected_3_gram = Flatten()(max_pool_3_gram)
fully_connected_5_gram = Flatten()(max_pool_5_gram)
merged_vector = layers.concatenate([fully_connected_1_gram, fully_connected_3_gram,
fully_connected_5_gram], axis=-1)
integration_layer = Dropout(0.2)(merged_vector) # <-------- [HyperParameter]
predictions = Dense(K, activation='softmax')(integration_layer)
#Criticality Model
criticality_network = Model(inputs=[gram_input],outputs=[predictions])
- SecureReqNet (deep) was an expansion of SecureReqNet (shallow). We included an extra convolutional layer, a max pooling, and a flatten function. The final tensor is a merged vector from the 3 initial kernels. A fully connected sigmoid layers was added just before the binary softmax layer.
- Alex-SecureReqNet (deep) was based on the proposed architecture by Krizhevsky et al., where 5 convolutional layers extract the abstract features and 3 fully connected reduce the dimensionality. This is the classical convolutional ImageNet network with a small adaptation in the final layer to induce binary classification.
- α-SecureReqNet (deep) was a modification of the Alex-SecureReqNet (deep) in the convolutional layers. The modification consisted in implementing the n-gram kernel strategy for text-based datasets (Han, et al., 2017). The input layer is a document embedding in the shape of a matrix. The first convolutional layer has a kernel of 7-gram size to reduce the input matrix into 32 vector feature maps. Later, it is applied a max pooling and a flatten function to obtain a column matrix. The second convolutional layer has a 5-gram filter followed by a max pooling and flatten function that merged 64 features. The third, fourth, and fifth convolutional layers are very similar to the original distribution in ImageNet but using 3-gram filters and 128/64 features respectively. Three fully connected layers went after the fifth conv layer to reduce the dimensionality and control the overfitting with the dropout units. The final layer is again a binary softmax layer (security vs non-security related).
# 1st Convolutional Layer Convolutional Layer (7-gram)
conv_1_layer = Conv2D(filters=32, input_shape=input_sh, activation='relu',
kernel_size=(7,embeddigs_cols), padding='valid')(gram_input)
# Max Pooling
max_1_pooling = MaxPooling2D(pool_size=((max_len_sentences-7+1),1), strides=None, padding='valid')(conv_1_layer)
# Fully Connected layer
fully_connected_1_gram = Flatten()(max_1_pooling)
fully_connected_1_gram = Reshape((32, 1, 1))(fully_connected_1_gram)
# 2nd Convolutional Layer (5-gram)
conv_2_layer = Conv2D(filters=64, kernel_size=(5,1), activation='relu',
padding='valid')(fully_connected_1_gram)
max_2_pooling = MaxPooling2D(pool_size=((32-5+1),1), strides=None, padding='valid')(conv_2_layer)
# Fully Connected layer
fully_connected_2_gram = Flatten()(max_2_pooling)
fully_connected_2_gram = Reshape((64, 1, 1))(fully_connected_2_gram)
# 3rd Convolutional Layer (3-gram)
conv_3_layer = Conv2D(filters=128, kernel_size=(3,1), activation='relu',
padding='valid')(fully_connected_2_gram)
# 4th Convolutional Layer (3-gram)
conv_4_layer = Conv2D(filters=128, kernel_size=(3,1), activation='relu',
padding='valid')(conv_3_layer)
# 5th Convolutional Layer (3-gram)
conv_5_layer = Conv2D(filters=64, kernel_size=(3,1), activation='relu',
padding='valid')(conv_4_layer)
# Max Pooling
max_5_pooling = MaxPooling2D(pool_size=(58,1), strides=None, padding='valid')(conv_5_layer)
# Fully Connected layer
fully_connected = Flatten()(max_5_pooling)
# 1st Fully Connected Layer
deep_dense_1_layer = Dense(32, activation='relu')(fully_connected)
deep_dense_1_layer = Dropout(0.2)(deep_dense_1_layer) # <-------- [HyperParameter]
# 2nd Fully Connected Layer
deep_dense_2_layer = Dense(32, activation='relu')(deep_dense_1_layer)
deep_dense_2_layer = Dropout(0.2)(deep_dense_2_layer) # <-------- [HyperParameter]
# 3rd Fully Connected Layer
deep_dense_3_layer = Dense(16, activation='relu')(deep_dense_2_layer)
deep_dense_3_layer = Dropout(0.2)(deep_dense_3_layer) # <-------- [HyperParameter]
predictions = Dense(K, activation='softmax')(deep_dense_3_layer)
#Criticality Model
criticality_network = Model(inputs=[gram_input],outputs=[predictions])
If you are using α-SecureReqNet, please consider citing (N. Palacio, et al., 2019)
Datasets
The context of our empirical study includes the four datasets (Embedding, Training, Validation, & Test) illustrated in the following table. These datasets are comprised of textual documents from different sources.
| Dataset Source | Embedding | Training | Validation | Testing | |
|---|---|---|---|---|---|
| CVE Database | 52908 | 37036 | 10582 | - | |
| GitLab Issues (SR) | 578 | 405 | 116 | 58 | |
| GitLab Issues (Non-SR) | 578 | 405 | 116 | 58 | |
| GitHub Issues (SR) | 4575 | 3203 | 915 | 458 | |
| GitHub Issues (Non-SR) | 47483 | 33238 | 9497 | 458 | |
| Wikipedia | 10000 | - | - | - |
- CVE Database: Our CVE Dataset was derived by crawling the National Vulnerability Database (NVD) and extracting the vulnerability description for each CVE entry. In total, we extracted over 100,000 CVE descriptions, however, in order to construct a dataset balanced equally between SR and non-SR text, we randomly sampled 52,908 CVE descriptions.
- GitLab Issues: To obtain a large set of diverse issues extracted from the issue trackers of a high-quality open source project we crawled the issue tracker of the GitLab Community Edition (CE) project. This project contains open source components of the GitLab suite of developer tools (used by millions) with an issue tracker that includes a sophisticated labeling system. To extract SR issues, we crawled this issue tracker and extracted issue descriptions containing "security" label. To extract non-SR issues we extracted entries without the "security" label and manually verified the non-SR nature of the descriptions by randomly sampling of 10% of the issues.
- GitHub Issues: Given the limited number of SR GitLab issues that we were able to extract, we also crawled the issue trackers of the most popular projects on GitHub (according to number of stars) and extracted issues with the "security" tag in order to derive a larger and more diverse dataset. Again, we randomly crawled non-SR issues and performed a random sampling to ensure the validity of the non-SR issues.
- Wikipedia Articles: If we trained our neural embeddings on only highly specialized software text extracted from issues, we risk our model not learning more generalized word contexts that could help differentiate between SR and non-SR issues. Thus, we randomly crawled and extracted the text from 10,000 Wikipedia articles in order to bolster the generalizablility of our learned neural word embeddings.
Interpretability
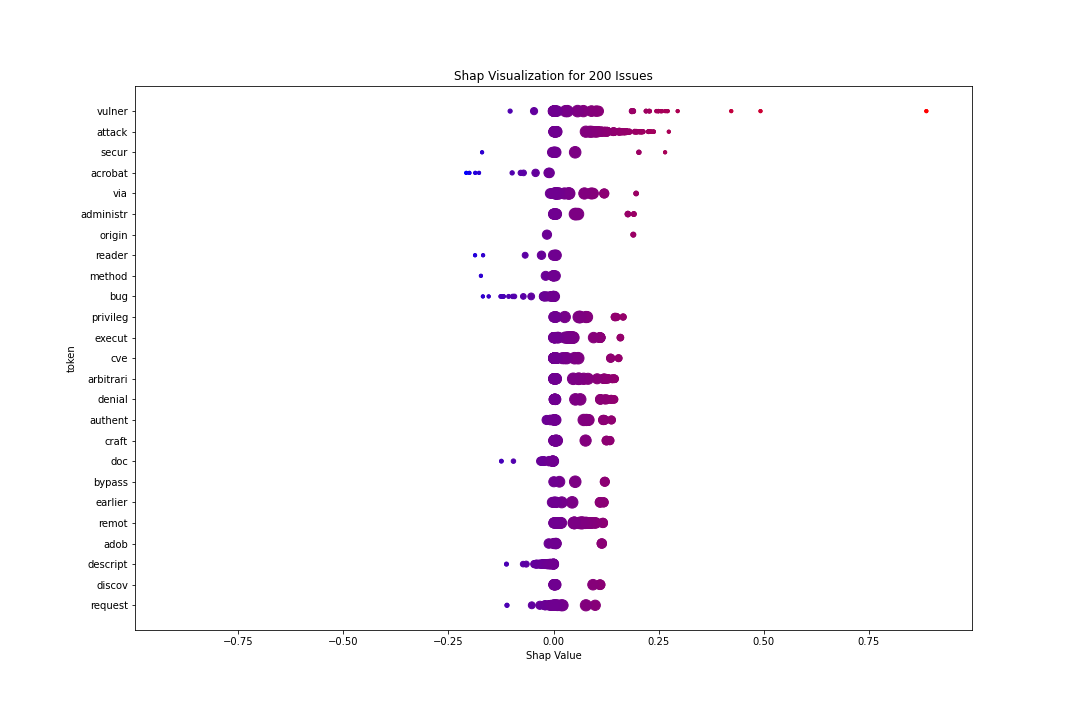
We used this library to generate shap values for alpha securereqnet. In the above generated graph, shap values were calcualted for 200 issues over a background of 400 issues randomly selected from our training dataset. The larger the value (more red, to the right) the more it contributes to the end prediction. The size of each dot represents its location along the normal distribution (larger around clusters). Tokens such as 'attack', 'vulner', and 'secur' appeared to have the largest effect on a positive classification. On the other hand, tokens such as 'acrobat' or 'reader' contributed more to a negative classification.
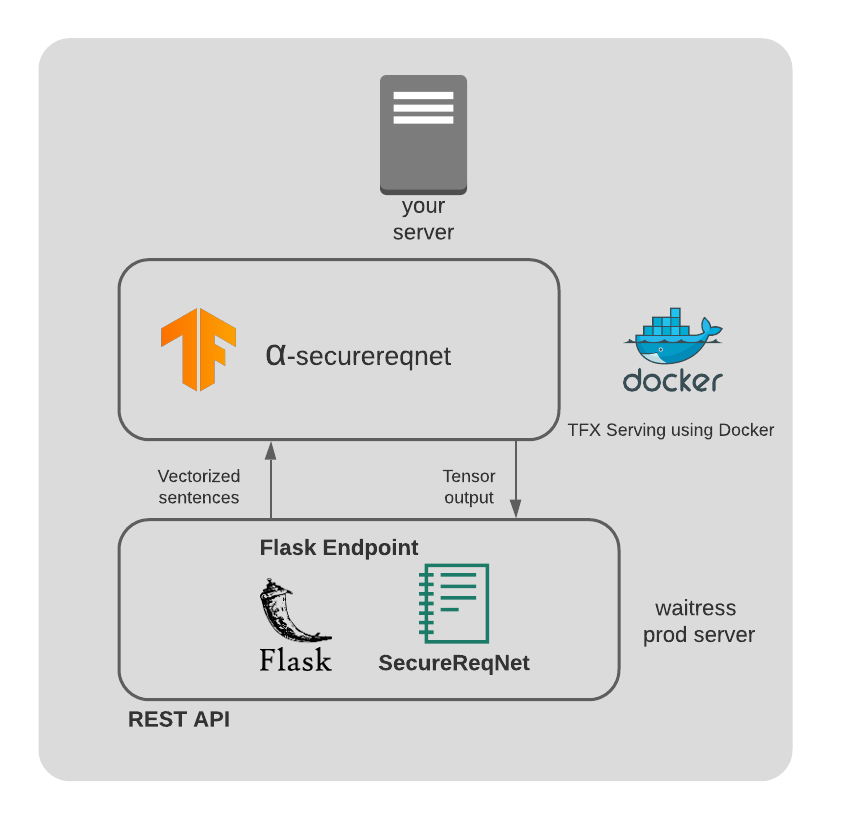
Here is what our production environment looks like for CSCI 435 project deployment